离奇问题,网络故障恢复后,无法重连到数据库?
问题现象
周末生产环境出现了一个奇怪的问题,部署在 k8s 容器中的 SpringBoot 应用连接到数据库的交换机出现了故障,交换机的故障恢复后,查询数据库的接口还是无法提供服务,试了很多次,日志中报出的异常依然是 Connection is not available,难道是网络还是没回复?
网络可能不通?那我们就 telnet 一下,网络是没问题的。最后我们使用 netstat 看一下和数据库的连接状态,状态是 ESTABLISHED,这个状态表示已经成功建立连接,但是连接只有一个,与我们配置的最小活跃连接数 10 的数量不相符,此时为了业务能尽快恢复,只好重启了应用服务。
事后,我们又查看了所有通过这个故障交换机连接数据库的应用,有的没有发生问题,有的没有经过重启,分别在 20 分钟和 120 分钟之后自动恢复了,于是我们开始在测试环境想办法复现这个问题并寻找解决方案。
问题复现
经过梳理,我们发现 20 分钟恢复的应用都部署在虚拟机上,120 分钟恢复的应用都部署在容器上,根据这两个数字,于是很快联想到 tcp_keepalive_time 这个系统配置,我们查看了虚机和容器的这个参数配置:
1 | sysctl net.ipv4.tcp_keepalive_time |
结果是,虚机是 1200,容器是 7200,换算一下,刚好是 20 分钟和 120 分钟,于是我们猜测,这个状态是 ESTABLISHED 的连接其实就是不可用的,即使连上了,我们也无法向数据库发送报文。
随后我们着手复现这个现象,并在测试环境的交换机中通过手动断开与数据库的连接来模拟故障,但是每次的试验结果都是,在故障恢复以后,应用和数据库的 TCP 连接立马恢复到 10 个,也就是最小活跃连接数,生产问题根本无法复现。
接下来,我们把目光投向 JDBC 建立数据库连接的过程,SpringBoot 的数据库连接池,毫无例外的都是使用 JDBC 连接数据库的,建立连接就要调用 getConnection()方法。这个方法,首先会建立 TCP 连接,TCP 建立连接后,连接就会保持在 ESTABLISHED 状态,然后发送认证信息,有没有可能问题就出在认证过程?如何模拟这种情况,我们用到了 iptables 这个工具。
iptables 是 Linux 操作系统中的一个用户空间工具,用于配置 Linux 内核中的 iptables 防火墙。它允许系统管理员定义规则来控制网络流量的进出、转发以及网络地址转换 (NAT)。iptables 通常用于安全性设置、防止未经授权的访问、管理网络流量等。我们回顾一下 TCP 三次握手的流程:
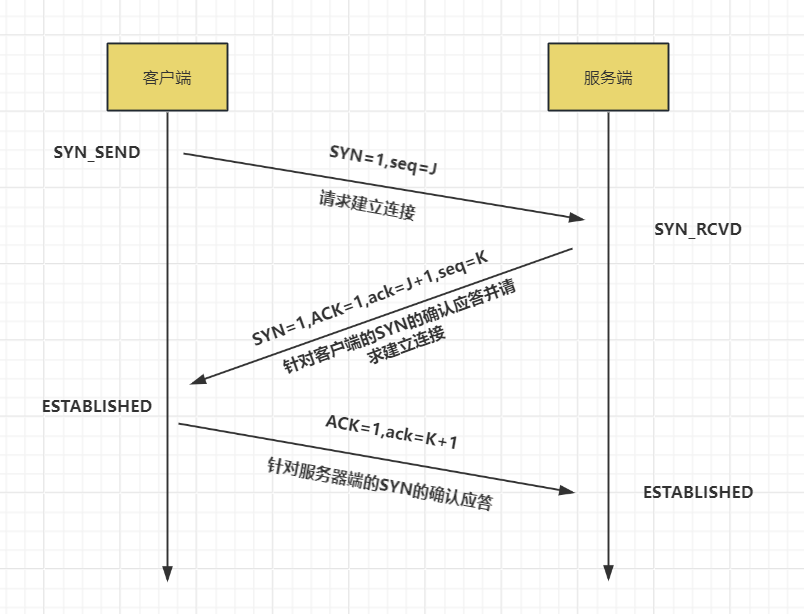
我们利用 iptables 屏蔽除 TCP 以外的三次握手,就能够达到目的了:
1 | iptables -A OUTPUT -p tcp --dport 2883 --tcp-flags SYN SYN -j ACCEPT |
这四个命令,大致意思就是允许客户端和服务端(端口为 2883)标志位为(SYN)、(SYN,ACK)的通讯包,分别对应 TCP 握手的前两次握手。允许客户端发送向服务端发送标志位(ACK)的通讯包,对应 TCP 握手的第三次握手。丢弃所有来自端口 2883 的标志位为( ACK)的通讯包,这样我们就达到了允许 TCP 成功握手,但是认证报文无法收到响应的问题。
通过这个方式注入故障,生产的问题终于复现了!注入这个故障后,和数据库的 TCP 连接逐渐降低到 1 个,且状态是 ESTABLISHED,随后我们移除故障,应用仍然没有恢复,经过了 tcp_keepalive_time 后,和数据库的连接数恢复到最小活跃连接数,问题就此复现。
最后一个问题
为什么故障恢复后,连接池不会恢复,我们翻看了 HikariCP 连接池的源码后发现,填充连接的线程,是一个单线程:
1 | private synchronized void fillPool() { |
复现过程中,我们通过 jstack 查看应用堆栈信息,该线程卡在 getConnection(),处于 socketRead 状态,这样就再也不会有新的连接建立了,应用不会恢复的问题也找到了!后来我们测试了 Druid 连接池,也存在这个问题,由于我们用的是 HikariCP,Druid 的源码我们就没有研究了。
解决方案
首先,我们要改 HikariCP 的源码的,简单的把 addConnectionExecutor 的线程数调大?当然不行,故障时间长了,问题还是会出现。
我们找到了这个任务里真正建立连接的代码,把他交给一个线程去处理,并配置了超时时间,超过这个时间,就强制销毁这个线程,这样 addConnectionExecutor 就不会阻塞了。在 PoolBase 里的 newConnection 方法里
1 | // doConnectionExecutor 是新定义的线程池,核心线程数和最大线程数都是 1 |
这样看似会不断重建线程,影响性能,实际上,只要不出现故障,就没有影响,线程数还是 1,出现故障,这点性能也就无所谓了。这样改,addConnectionExecutor 就不会阻塞了。
这样有一个风险,如果 tcp_keepalive_time 过长且故障一直不恢复,会建立很多无用的连接,连接数会一直膨胀,把服务器端口占满。如果 tcp_keepalive_time 合适的话,这些无用连接都会被关闭,最终在 tcp_keepalive_time 窗口期内维持一个定值,问题也不会太大。
最后,k8s 的 tcp_keepalive_time 不会继承宿主机的这个配置,默认是 7200 秒,如果没有高权限,比如我们的生产环境,是没办法在 Dockerfile 里改的,这个时候需要用到 initContainers,在 deployment 的 yaml 文件中添加如下配置:
1 | initContainers: |
至此,这个问题基本上解决了!
本文作者: twl
由 iMaeGoo 代为发表
离奇问题,网络故障恢复后,无法重连到数据库?


